【参加レポ】巨大化するスタンプ、きせかえ販売システム その危機と復活の記録 【LINE DEVELOPER_DAY 2015】#linedevday
4/28に開催されたLINEのエンジニアチームの様々な経験を、未解決の課題も含めて共有する技術カンファレンス、
に参加してきたのでその時のまとめ。
スタンプショップの裏側についてのお話です。
他のセッションは以下からどうぞ







Haruki Sato様

ユーザー数 or ユーザートラフィックの増加、システムの複雑度によるサービスの規模
- LINEのユーザー * ショップサービスをりようする割合 = ショップサービスのユーザー
- 利用する割合に注意すべき場合
- 人気商品の配信開始 -> アクセス増加
- リアルタイム性の高いイベントなどの大規模なイベントでピークが高くなる
- 公式アカウントからスタンプ配信するなど
- きせかえの場合はアプリアップデートのタイミングでアクセス増加
- サービスの成長と性質に注意
事例
スタンプショップの例
- 2014/02にDBシャーディングの追加をした
- 現在はMySQLでのAPplication embeddedなsharding
- user_hash % 12でsharding keyは行っている
- 拡張のきっかけ
- 各地域のユーザー対象の無料スタンプ配信
- 拡張しないと場合によっては運用でカバーする
- イベントが行う範囲が広い場合はやる時期をずらしたり、大きなプロモーションをする場合は小さくしながらプロモーションしたりした
- もっと自由にイベントをしたいので拡張性の必要があった
- 問題
- Sharded DBに関連するプロセスがたくさんあった
- 変更部分はAPI、バッチなどすべてのプロセスに適用しないといけない

- 反省:変更部分が複数になったことによる煩雑さ
- DBとApplicationにまたがったロジック
- ロジックが分散するのは大変
- 同じロジックは1箇所にあるのがいい
- ロジックの一元管理方法としてはDBへのアクセスを目的に応じて抽象化する
- APIやバッチなどのロジックをひとつにまとめた
- DBアクセスをすべて引き受けるサーバを用意するという手もある(DB access gateway server)
システムの複雑度
- アプリケーションの中での問題
- APIサーバの消費メモリを減らさないとサービスができない事があった
- スタンプショップの危機!
- APIサーバが複数あって一つのDBサーバを参照してたころ…
- ついにAPIサーバが20台で128Gで動かしていた
- サーバーの再起動に3時間かかっていた
- DBサーバのCPU負荷が増大していた

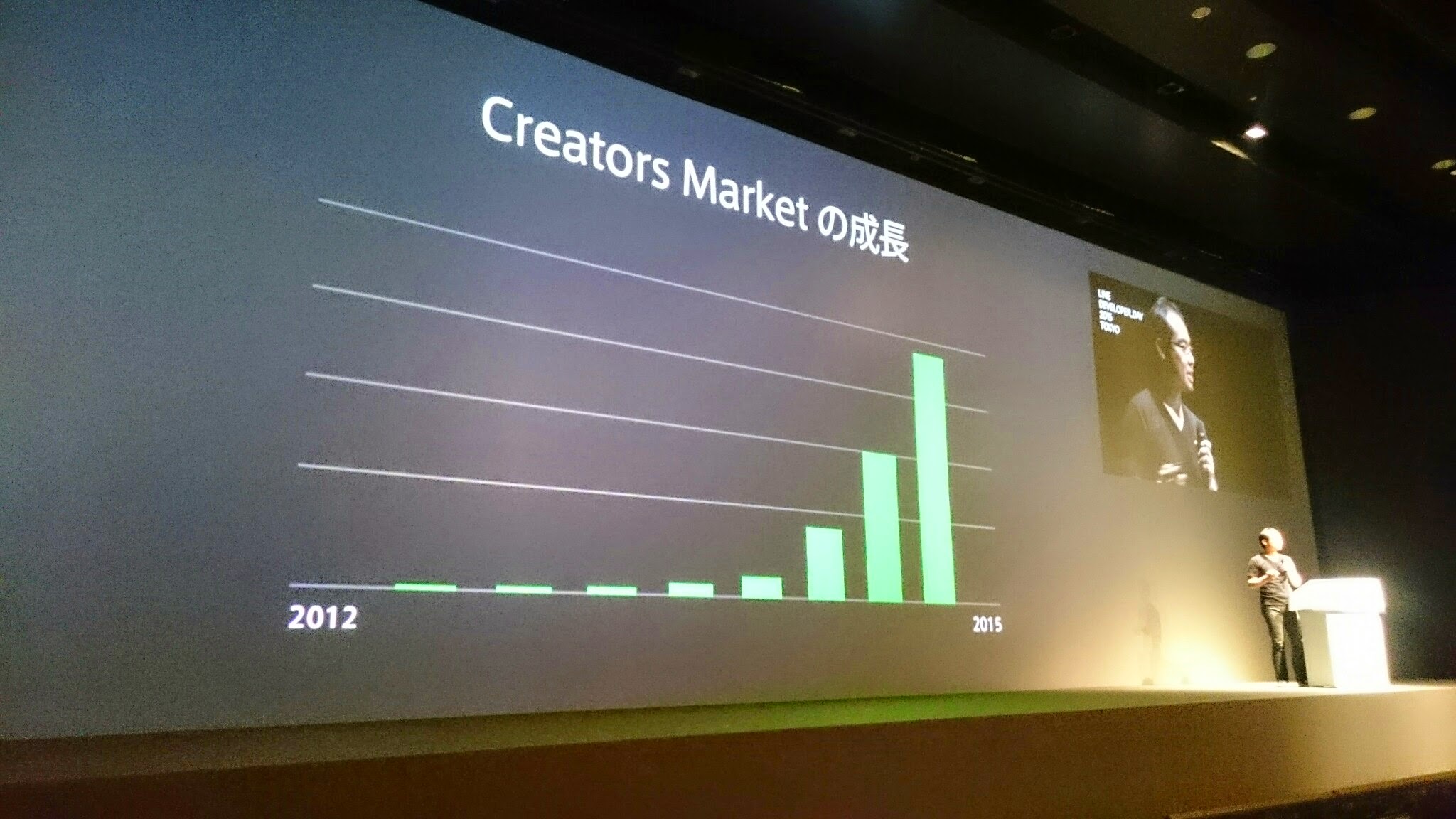
- 問題はNaiveなAPI実装、CreatorsMarketの開始
- APIサーバとして実現したいこととサービスとして実現したいことが問題になった??
- APIサーバの要求事項
- 可能な限り早いAPI
- 接続状態がクオリティにつながることが多い
- 遅いAPIはサービスの不安につながる
- サービスの要求事項
- 地域ごとに商品をつくることがある
- アニメーション、サウンド付きのスタンプはクライアントのバージョンによる出し分けなどをしている
APIの例
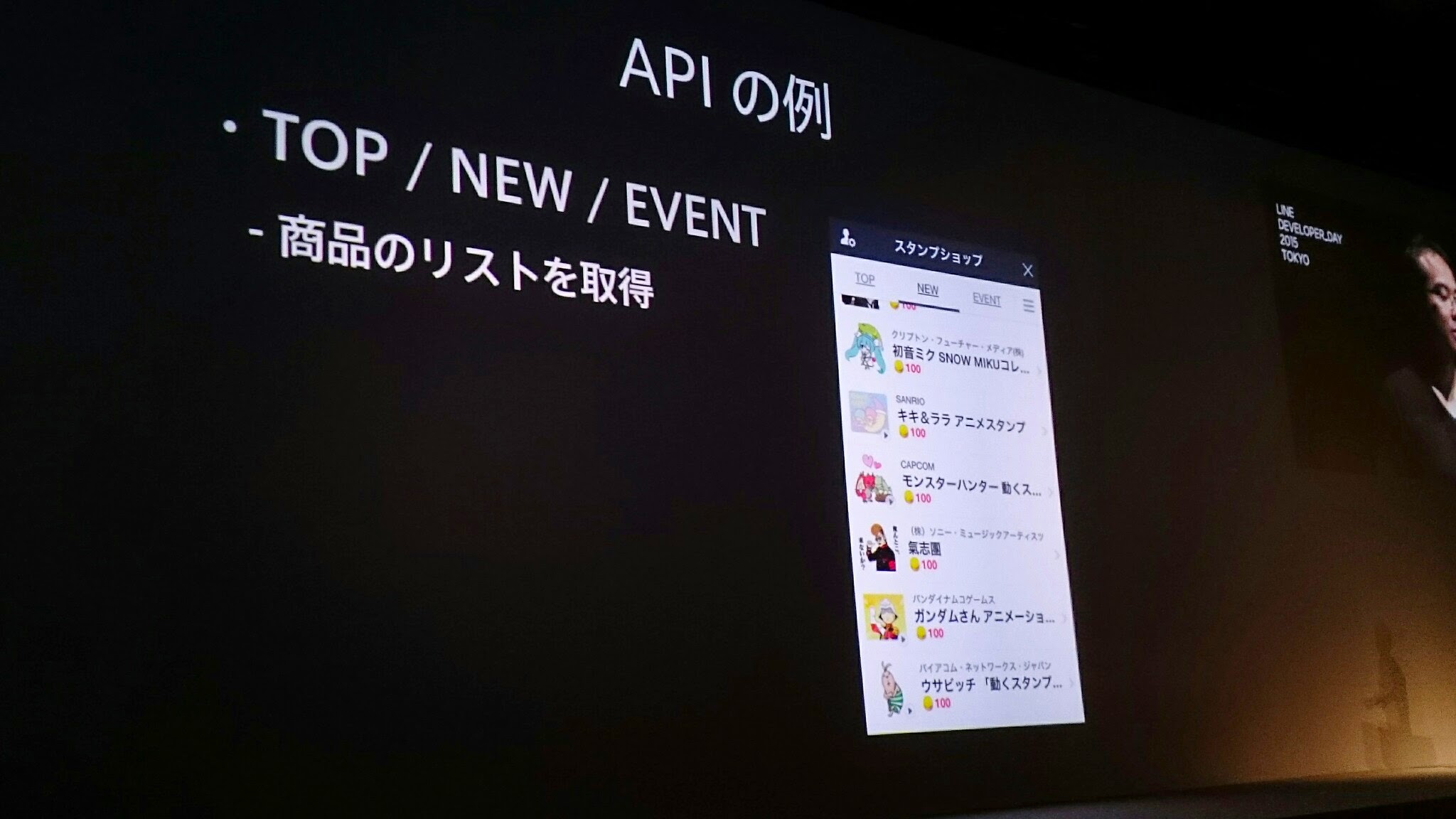

- 商品のリストを取得
- 素朴な実装をしていた
- 崩壊の始まり
- 商品数が増えれば増えるほどメモリ要求量の増加
- 事前計算はすべてのAPIサーバが別々に実行していたので必要時間が長くなった
- スタンプオーダーが数万ふえているが、それぞれ一つのDBを参照しているためにDBサーバの負荷も大きくなった
- 方針として最初にインメモリーで保持しないといけない内容を除去する方向でたてた
新構成
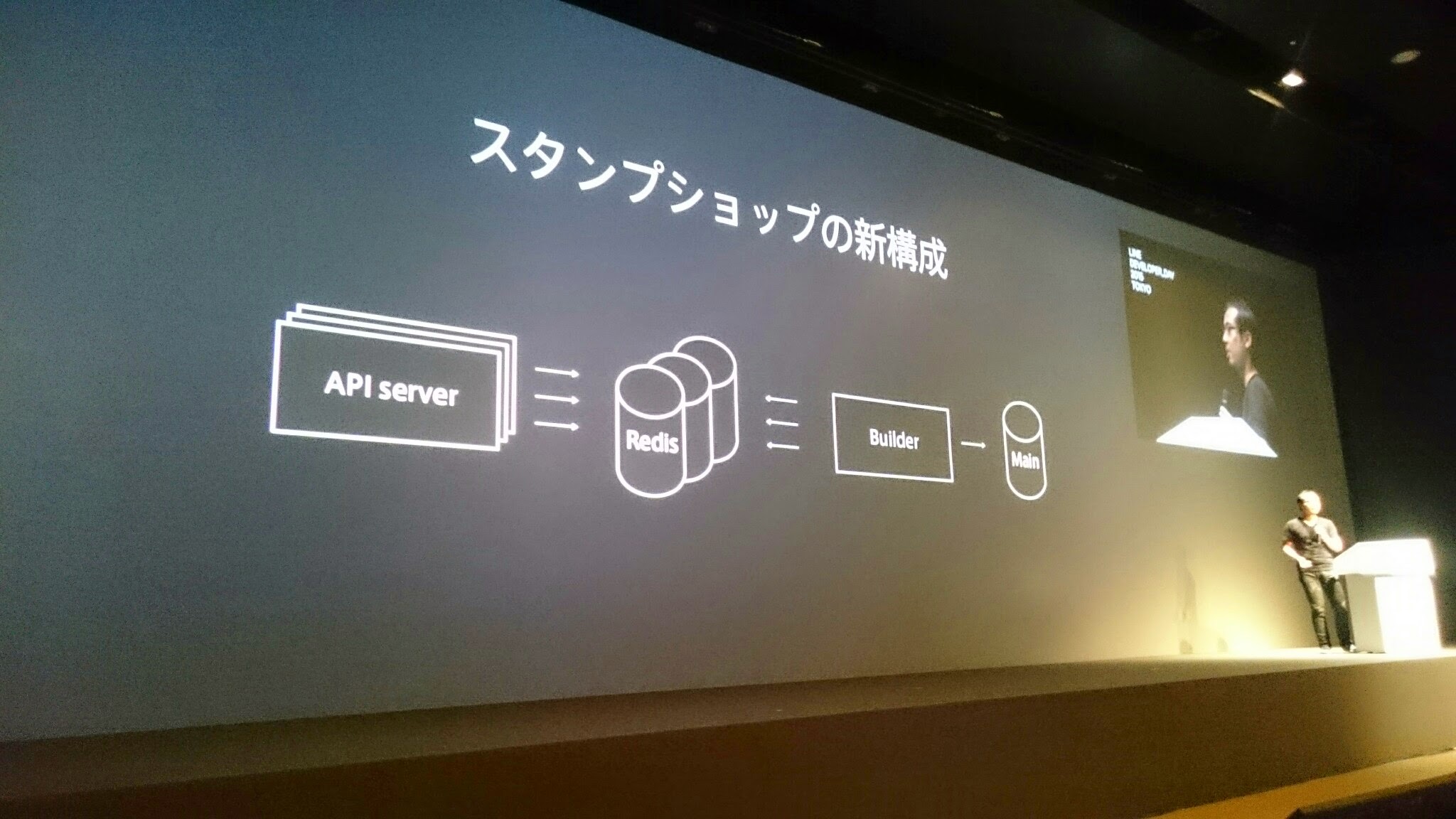
- APIサーバがRedisを参照する
- Redisに入っているべきデータはキャッシュビルダーが持つ(事前計算するところ)
- メインのデータはDBに
- 新構成にしても1台だけでの性能は限界がある
- そのためRedisをクラスタ化している
- LINE’s Shareded Redis clusterを活用できた
- 関連チームの助言や連携、既存redisモニタリングツールも利用できた
- APIサーバの消費メモリ削減はredisに行くことで解決できた
- redisクラスタを利用することで水平分散が可能になった
- メモリが足りない場合はクラスタにノードを追加する
- 事前計算はキャッシュビルダーに集約することで必要なリソース管理も容易になった
- DBのCPU負荷は直接クエリーを行うのはキャッシュビルダーになったので負荷が効率化された
- 苦労話
- APIの中にあったロジックを外部に持っていったために、本当に計算結果が一致するのかというのに気を使った
- サーバー再起動に3時間になっていたため、iterationが遅くなった
- この問題の教訓としては、Naiveな実装をするときは、その影響やトレードオフについて認識する
- 手当は迅速に
- 迅速に行うためには、準備や交通整理が大事
まとめ
- システムの規模
- 成長していくユーザー数と、サービスがどのように使われるかの性質やパターン
- 複雑度
- 高品質なサービスの提供をするためにさらに追加や改善していく
- 扱うデータ量が増えていく
- 複数の要素が同時に組み合わせられることで爆発する
- スケーラブルに解決するという技術・手段を適切に使うのが大事
- サービスのいろいろな要求にスケーラブルに答えられるように心がけたい
- 全体の量、実現したい質も大きくなるにつれて規模や複雑度は大きくなっていく
所感
最初は速度重視で実装はしていてもいずれアクセス量が増えていくとそれでは対応できなくなるので、柔軟に構成を変えるというのが大事ということを改めて悟りました。
最初の実装の時にスケーラビリティを考えて実装できるのが一番いいですが、早さと引き換えもあるとは思うのでなかなか難しいところではありますね。










