#jpoug ハイパフォーマンスを実現する設計方法とSQLチューニング実践講座@JPOUG> SET EVENTS 20151017のまとめレポ

Oracleの様々な話題を扱うJPOUG> SET EVENTS 20151017というイベントに出てきたのでそのまとめ。
今回はハイパフォーマンスを実現する設計方法とSQLチューニング実践講座というセッションのレポートです。
SQLチューニング入門の方必見です!
他のセッションは以下よりどうぞ。

ハイパフォーマンスを実現する設計方法とSQLチューニング実践講座

なぜDBはパフォーマンス問題の温床なのか
- 遅い理由1;データ量が大きい
- 遅い理由2:ストレージがシングルボトルネックになりがちでスケールアウトしにくい
- shared nothingという構成をとれば横に並べられるが、データも分かれるのでこのケースはあまり多くは取れない
- shared nothingはアクセスするユーザが全然違ったりデータの保持するものが違うといったケースならばとることはできるが、データをまとめるというという要件に応えにくい
ディスクに触ると不幸になる
- I/Oネック状態になると他のリソースを増やしても効き目がない状態になってしまう。
- 待機系イベントのdb file sequential read, scattered read, direct path read, log file syncなどが9割を専有されてる状態など、ディスクが詰まりすぎてOracleは何もできなくなる
ディスクレス = 勝ち組
- どうしたらディスクに触らずにシステムを処理できるかがパフォーマンスの要点
- オンメモリ、SSDを増やして金を積むやり方:アメリカ人はこのケースで解決するのが多い
- keep_bufferにメモリを固定するとうまくいく
- スモールテーブルのやり方
- ディスクからとってくるデータ量が多いなら一番良く使われるテーブルを小さくすればいい
- トランザクション系の詳細テーブルをなんとか小さくしたりする
- テーブルを小さくするのはパフォーマンス的にはいいことしかない
- スモールクエリにするやり方
- なるべく、結合などの高コストを避ける
- シンプルなSQLを使って結合をする
- 1回のアクセスでとるデータが小さくなる
- 実行計画の最適化
- ベンダー的には推奨される方法ではないが、ヒント句やSPMを使ってチューニングをする
スモールベースボール
- 参照頻度の低いデータはメインテーブルには持たず、履歴テーブルやバックアップテーブルに移しましょう
- パーティションやマート(MView)で物理的なアクセスを分離する
- 画面設計でフリーダムななにも条件を指定しない非定形検索はしないようにする
- 範囲検索するときでも3年検索するときは1年検索を3回にわけたりする
結合の性能問題
- テーブルを複数スキャンするのは無駄なI/Oコスト
- 結合が増えれば増えるほどパフォーマンスが悪くなっていく
- 安定性が犠牲になっていく
- 結合アルゴリズムや結合順序がかわりパフォーマンスが突如変わったりする
- Nested Loops/Hash/Sort Mergeが大体選択されるがそれがどんどん変わってしまう
- 検索条件のパラメータによるヒット件数の変動
- 与えられるパラメータによってヒットするデータの範囲は変わる
- データが均等に分散してればいいが、ヒットするデータとヒットしないデータに分かれる
- 結合を使わないのが根本的解決法
- window関数やcase関数を使って結合をとることができる!
サンプルテーブルのデモを使った説明
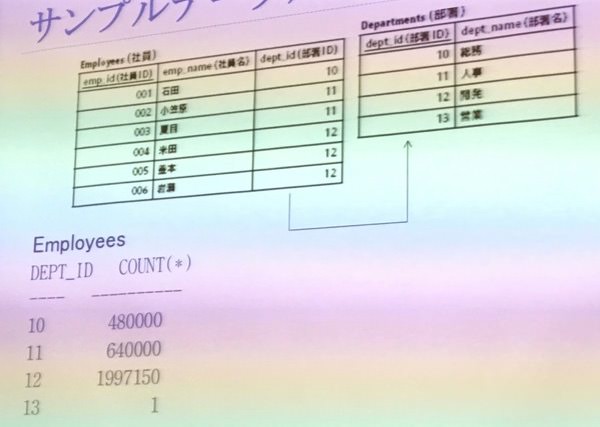
- 社員のテーブルが重要
- dept_idを使って結合SQLを考えます
- dept_idが10, 11は数合わせで入れてるので重要ではないが、12と13のレコードが大事
- 12は極端にヒット件数が多い検索条件
- 13は逆に1件しかヒットしない最小ケース
- 簡単に言うと開発者が199万人もいて営業が一人しかいない会社(なんて開発力のある会社!)
駆動表の変動
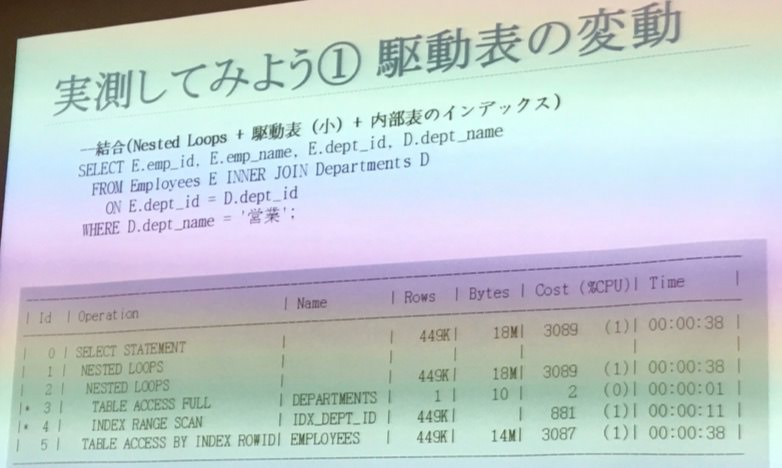

- nested loopで非常にいい実行計画
- 駆動表が小さいテーブルで、内部表のインデックスで結合キーをあたりにいける
- どのDBでもつかえる基本になる形
- 内部表のインデックスを使うことでnested loopをスキップできる
- 部署テーブルを駆動表にして社員テーブルをあてにいって1件だけ選択される
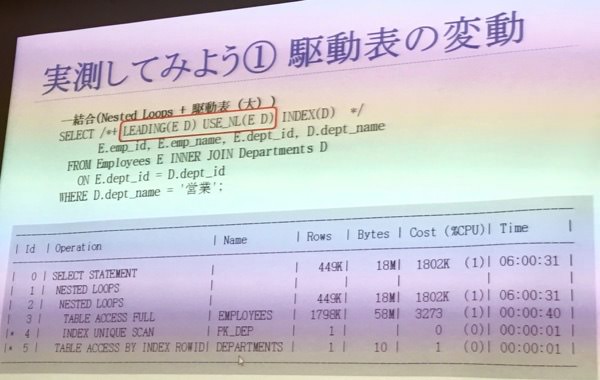
- 駆動表がおおきくなるとどうなるかということで、内部表と駆動表の結合を変えてみる
- 社員テーブルが駆動表、小さい部署テーブルが内部表になっている
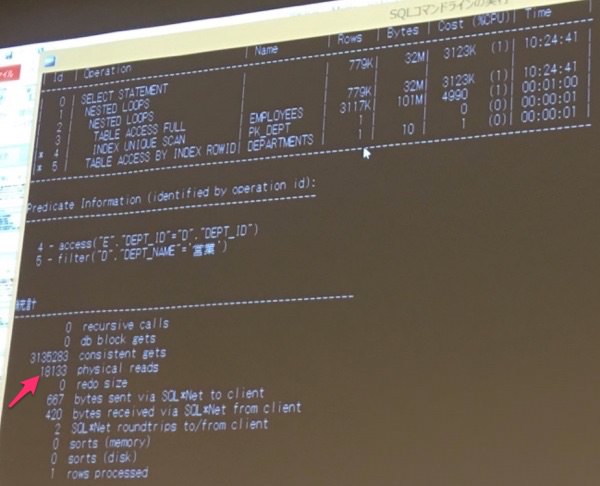
- 内部表のループはしていないという部署テーブルが駆動表の時の条件とおなじだが、内部表と駆動表がひっくりかえるだけでパフォーマンスがおちている
- 物理アクセスがとても増えている(先程はphysical readsが23だったが、今回は18133になっていた)
- 内部表が小さいとnested loopのときのインデックスのスキップができる
- しかしいつもこのケースでいけるわけではない
ヒット件数の違い
- 実行計画は同じだが、ヒット件数が違うSQL

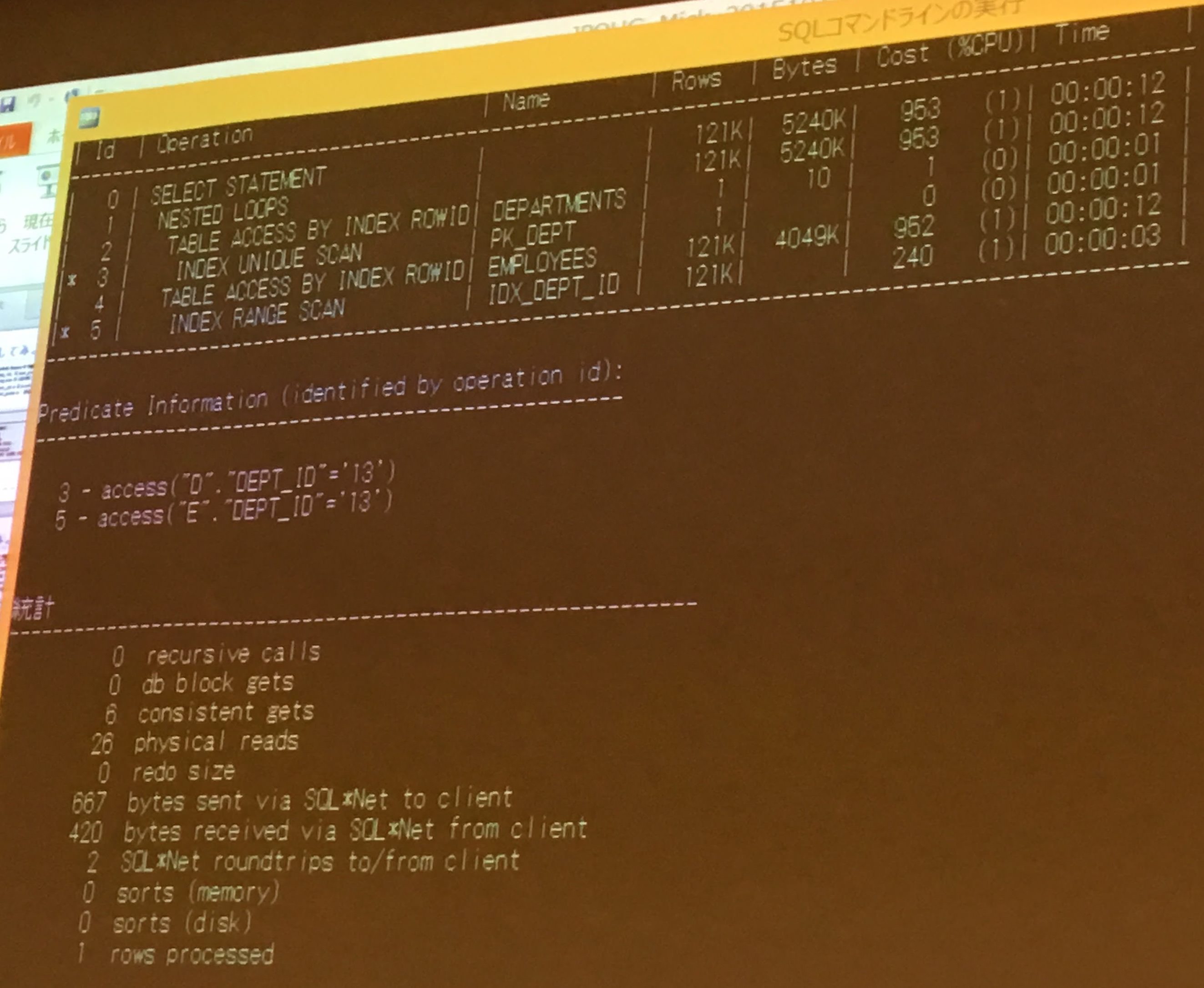
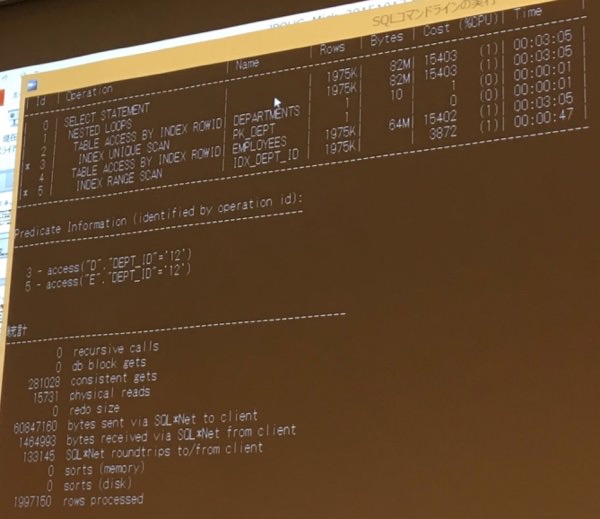
- 一番最初にやったのと大体おなじだが、件数が違うのでFULL SCANでも変わらない
- 内部表のヒット件数が多いSQLは中々帰ってこなくなる
- nested loopを使う時の弱点は、絞りがきくときだけしか使えない
- ヒットするものが多いとインデックスのレンジスキャンが遅くなってしまう
- bindを使っていると同じ実行計画が使われてしまうので困ってしまう
アルゴリズムの変動
- テーブルが多い時のハッシュはnested loopよりもはやくはなるが、めちゃめちゃはやいわけではない。しかし、nested loopにない結合を使った時の安定性が確保できる場合があるというメリットがある
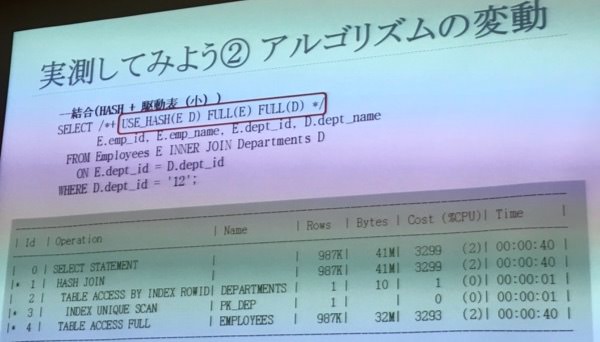
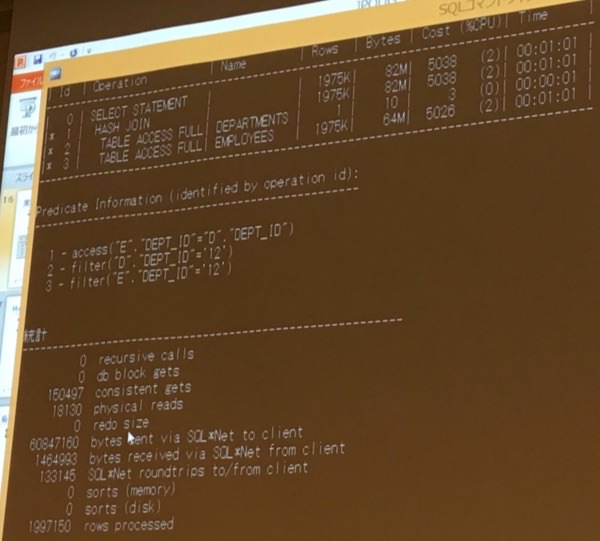
- デモではhashの駆動表が小さくなるように投げている
- 大きい方が駆動表になっても同じくらいになる
- 駆動表がひっくりかえっても大きな違いが出ない
- 本当は駆動表が小さいほうがいいが、nested loopよりはパフォーマンスが変わりにくい
- しかしハッシュの落とし穴はPGAの消費量が多く、セッションが重なるとtempを使うようになってしまう
- 複数セッションから大量に発行されて初めて発覚するので単発性能だと気づきにくい
- あまりハッシュを使ってもOKというわけではない
- OLTPでハッシュを使うのは危険
- しかしMySQLだけはnested loopしかないのでhash joinが使えない
- ミックさんの想像ではハッシュを使えたらtempに傾いてしまうからあえていれてないのではないかと考えている
実行計画の安定性
長期的には皆死ぬ
- 実行計画変動によるスローダウンは予測不能で不可避
- 実行計画によるぶれ問題の解決法は秘儀・統計情報を凍結したり、パラメータをオフにしたりする
- 安定性が欲しい場合はそのような処置をするところもある
- もう一つの解決法は難しいSQLを書かないで結合をやめる。
- 一意検索のSQLだけでやってとってきたデータをJavaなどのアプリ側でぐるぐる回して検索させる
- もはやDBはただのファイルになる
- 遅いけど安定はする
ぐるぐる系dis
- 性能的には遅い、チューニングやりにくい、といいところはない
- チューニングするにはアプリケーション自体の改修になってしまう
- しかし、実行計画が安定するメリットは捨てがたい
- 突然運用で遅くなるのが嫌というの強ければこれはいいのかもしれない
まとめ
- DBが第1ボトルネック状況は今後も変わらない
- ストレージ革命で状況は好転するかもしれないが、中身がパンパンになるのはまだ続くかも
- 設計で頑張ってスモールベースボールでコストを抑えるのはなくならない
- 実行計画の変動によるリスクとメリットは事前によく考えておく
@mogmetの所感
とてもわかりやすく面白いセッションでした。
駆動表と内部表の違いなど全然知らなかったのでパフォーマンスチューニングできるようにもっと勉強が必要だなと感じました。
MySQLだけはnested loopしかないという違いもあって面白かったです。
駆動表はなるだけ小さくなるように意識してSQLを書いていこう!!と密かに決心したセッションでした(なかなかSQL書く機会ないけど)











