#mysqlcasual MySQLの最先端を行く現場人が集う MySQL Casual Talks #8に行ってきたまとめ

久々にMySQLのゆるふわ〜と見せかけてガチなお話もきけるMySQL Casual Talks #8に参加できたのでその時のまとめです。
超小規模環境のMySQL

とあるガラケーコンテンツのお話
- オーソドックスなLAMP構成で朝起きるとログイン出来ないと問題が毎日あった
- エラー内容はDBに問い合わせができない状態
- MySQLの接続がタイムアウトしていた
- データが流れないとサーバ側から接続をきられる
- apacheのpreforkで夜にアクセスが少なく、たまたま処理をしていなかったプロセスがmysqlにアクセスしようとすると接続できなかった
- Morning bugといわれるらしい
- pingやtcp_keep_alive設定すればいいのではと言われるが、超小規模サイトでは毎回接続すればいいのではという結論になった
- ちなみにこのサイトの会員数は10人! -> それ全部テスト端末では?!
- 企画の人は大きくなる!というが、大体大きくなる前に終了していくサービスが多いので、1つくらいあたった時に捻出できるリソースは準備しておく程度でいい
小規模しかやらない開発者は…
- 長年SQLのパフォーマンスを考えなくなる
- N+1問題以前にselect * from tbl;を集積関数を使わず、arrayでcountして捨てるみたいなこともあったりする
- ちょっとアクセス増えると楽しい!
小規模でもMySQL
- 小規模と言ってもファイル管理にするのはファイルロックをちゃんと考えないといけないので危険
2015年の小規模
- クラウド全盛時代、RDSやAuroraで立ち上げてやる
手元にある小規模
- 社内の管理ツールなどでは素のPHPで都度接続のほうが健康的だと思っている
- 今はAWSなどのクラウドで頑張ればいいのではと思っている
MySQL Lv.1 ~ MySQLの基本的なあれこれ〜

Storageのお話について
- FEDERATEDは他のMySQLサーバにクエリをプロキシしてくれる
- BLACKHOLEエンジンはどんなデータをインサートしても消えていくテーブルになる
- サーバのスペックが低い時にある巨大テーブルがinnodbバッファプールを溢れさせてしまうというときに、そのテーブルをBLACKHOLEにしておけばメモリにのせずに済む
MyISAM
- 参照が速い
- 更新時はテーブルロックをかけるので更新が詰まりやすい
- トランザクションはサポートしない
- リクエストが複数来た時に起こる問題が見つかるかも
- 基本的には使わないほうがいい
InnoDB
- クラスタ化インデックス
- プライマリキーでの参照が速い
- 更新時は行ロックをかけるのでMyISAMよりはいい
- トランザクションをサポートしている
- 5.5から標準のストレージエンジンになりました
設定
- 実践ハイパフォーマンスMySQLをよんでおきましょう
- あるサービスでリクエストが増えた時に、DBやアプリが詰まったことがあり、コネクション数が同時にすごい発生して、TCPのコネクションが確立できないことがあった
- back-logをあらかじめ増やしておくと解決できる
- slow queryは基本的にon
- memory
- thread_cache_size:スレッドを作ってアプリを処理するが、スレッドを使い回す時にどれくらいキャッシュを残しておくか
- wait_timeout : クエリを一切発行しない時間があるとタイムアウトする(この時ちょうど発表時のマイクもタイムアウトして音が出なくなっていた)
- thread buffers
- スレッドごとにsort_buffer_size, read_buffer_size, read_rnd_buffer_sizeなど、バッファーを持っている
- read_rnd_buffer_size: インデックスを使えてないクエリで使われるが、インデックスをうまく使えていれば大きくする必要はない
- binlogs
- log-binを設定するとログを吐くようになる
- max_binlog_sizeを300Mとか設定すると300Mこえると次のバイナリになったりする
- binlogが大きくなると容量に困るのでexpire_logs_daysの指定に注意
- replication
- slave-compressed-protocol:レプリケーションのデータが圧縮されて送られるようになる
- slave-net-timeout: ネットワークが不安定なところだと、レプリケーションが突然止まったりする。その時にレプリケーションが切れてリトライするとき、デフォルトだと3600秒のレプリケーションが止まることになる。そこでこれを小さくしておくといい
QueryCache
- query_cache_type
- 更新が中心のDBでは基本無効
- select文にヒント句をいれるとクエリキャッシュが効くDEMANDというオプションが有る
- InnoDB
- innodb_buffer_pool_sizeを指定してデータとインデックスがメモリに乗るようにしましょう
- innodb_buffer_pool_dump_at_shutdown / innodb_buffer_pool_load_at_startup : 終了時にメモリをダンプしてくれて、起動時にロードしてくれる
- innodb_log_file_size: 更新ログのファイルサイズ。更新が多い時は増やしておくと、innodb_buffer_poolの間隔が長くなるのでパフォーマンスが上がる
まとめ
- MySQL使うときはInnoDBを使う
- 設定とクエリのチューニングが大事
- 実践ハイパフォーマンスMySQLを読むといいです
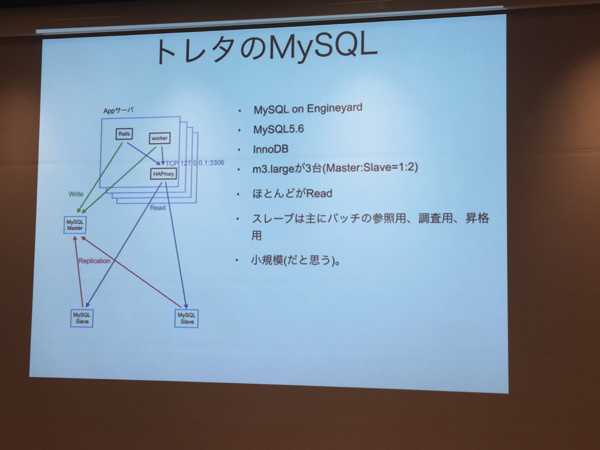
トレタのMySQL

- トレタは飲食店向け予約管理アプリケーション
- アクセスのピークは18:00くらい
- 金曜 > 他 > 土曜 > 日曜の順で多い
- トレタはEngineyardで稼働している
- 一部機能はAWSの機能を使ったりもしている
構成
- m3.largeのMySQL5.6が3台 (Master:Slave = 1:2)
- 殆どがRead
- Likeフィルタによる全文検索が割りと動く
- キューっぽい使い方をしている
- 大規模に比べると構成がシンプルになりがちなので運用が楽
全文検索
- InnoDBのフルテキストインデックスやMroongaも使っていないが、その理由はストレスなく動いているから
- フルテキストインデックスは外国の言語は大丈夫だが、日本語は単語ごとに見るのが難しいので微妙なところ
- Mroongaは友人に聞くと運用で苦労していると聞いた
- ※蛇足
MySQL標準の全文検索の日本語サポートはは5.7から。なので5.6の場合は登録の際に分かち書きにしないとダメなはず。5.7ならmecabとか使えるので一応動くはず(まともに試してない #mysqlcasual
— ITOH Hiroyuki (@i_rethi) 2015, 11月 20
- それぞれのレストランの中でヒットするワードなどを検索する
- レコード数が少なければ案外なんとかなっている
- 部分一致検索はなぜ遅いか -> 前方一致検索は効くが、先方に%があるとインデックスがきかないからです
- バリデーションをしっかりせず、「select * from t where col like ‘%’」といったSQLが流れてCPU100%になったりしたことがあった
MySQLでキューのようなことをする
- バッチサーバをおいて、バッチを動かすよりはrailsで全部やってしまっている
- 定期的にworkerが一斉に動き出してMySQLに参照/更新を行ってメールを送る機能について
- workerはsidekiqというgemを使って実装されていて、これはrailsに張り付いて非同期処理を行えるがバッチ処理もworkerにやらせている
- ステータスを処理していない各ワーカーがステータスをとりにきて、ステータスを1に書き換えるなど行っているが正直悪手ではある
- cf: MySQLでqueueっぽい機能を実装する
大規模より運用は楽
- 大規模時代はMySQL側でシャーディングや特定のテーブルだけレプリケーションするレプリケーションフィルタ、innodbの圧縮などを使ったりした
- ちなみにinnodbのcompressedを使うと容量が1/3くらいになる
- 小規模の今はinnoDBだけで、多少のスパイクはあるが、コンフィグは基本的なものだけケアすればいい
- 構成がシンプルだから楽。大規模でもシンプルは保つべき
- Railesのmigrationで運用が回る
- 規模が大きくなるとalter tableが怖い
まとめ
- 小規模だと、多少のアンチパターンでも大丈夫。
- サービスはヒットするかわからないので著名なフレームワークやミドルウェアでやってくのがいい
- けどインデックスをきちんと貼るのは大事。スローログなどモニタリングはする
- シンプルな構成は大規模になっても保つべき
迫り来る課題
- 悪手からの脱却
- 用途に最適化されたミドルウェアの導入など、
- railsのmigrationに依存した運用からの脱却
ゆるふわMySQLフェイルオーバー

フェイルオーバー構成
- keepalivedをつかってVIPを使っている構成
- mysqlが死んだ時にkeepalivedがヘルスチェックに失敗し、二号機にフェイルオーバーする
VRRP
- ステートがマスターとバックアップと定義されている
- マスターは自分がマスターだというadvertiseのパッケとを流しており、それが途切れたらbackupがmasterになる
- マルチキャスト、ユニキャストで投げている
ヘルスチェック
- 今回のvrrp.confでは1秒毎にチェックして2回失敗したらFault、2回成功でbackup or masterになる
VRRP切り替え時間
- 2秒でステップダウンするので2,3秒でマスターが切り替わる
- masterがサーバごと突然死した場合は、backupがadvertiseのパケットを見ていて最長でも4秒で切り替わる
レプリケーション
- レプリケーションはシングルスレッドなので、マスターがマルチで書き込みに来るとスレーブがどんどん遅れていく
- 5.7からはマルチで書き込みができる
- レプリケーションが遅延ある場合に、keepalivedでそのまま切り替わるとデータの不整合が起こってしまう
- 不整合を防ぐために遅延のフラグをみて、readonlyのフラグを切り替えている
- show slave statusのGTIDとUUID表示、IOスレッド、SQLランニングしてるかなどをみている
フェイルオーバーデモ
- 小規模のデモ環境でmysqlを落としてreadonlyフラグが切り替わるのを見ます
- v001とv002という2台の仮想マシンでやります
- GTIDが1-20209まで実行されている状態
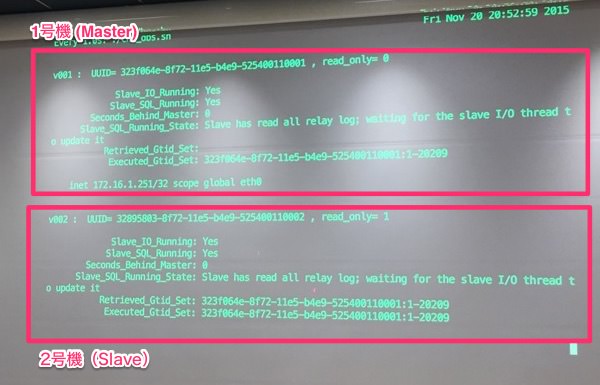
普通にマスターを落としてみると大体2〜3秒で切り替わります
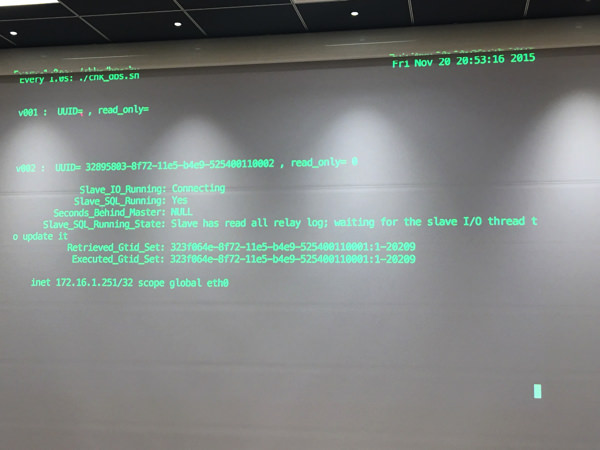
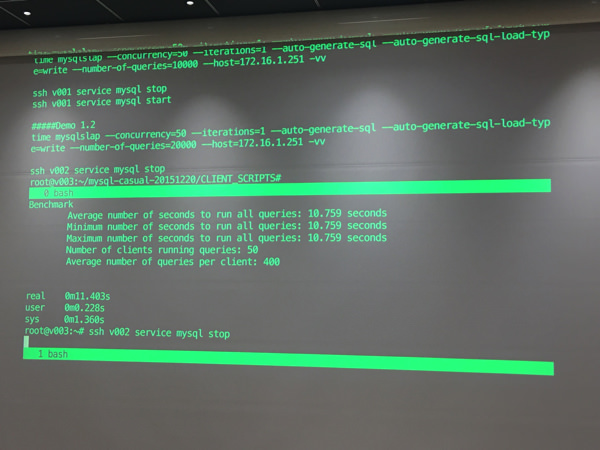
次にmysqlslapで1万クエリを書き込んでいじめて、スレーブに遅延が発生している時に落としてみます。
遅延中の図
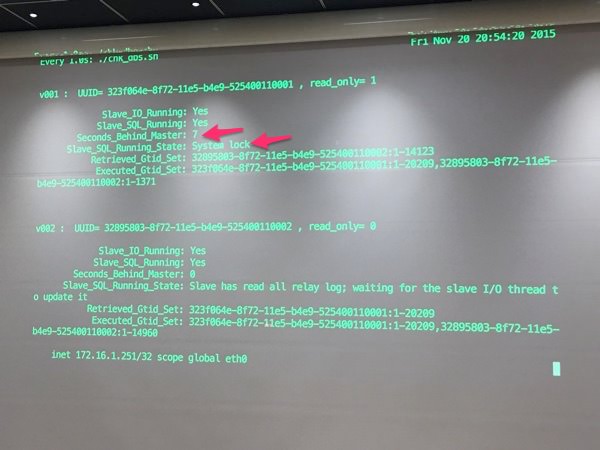
マスターを落としてみる(先ほどのデモの続きでやっているので2号機がマスターになっていた)
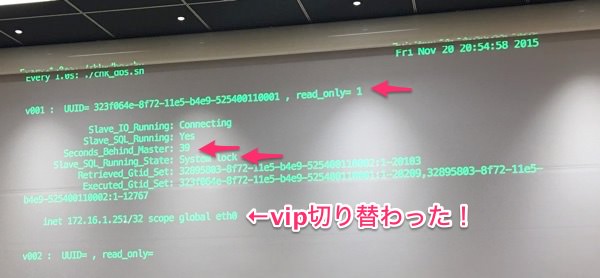
落ちた直後。まだスレーブは遅延しています。

VIPが切り替わりましたが、まだスレーブへのbinlog適用が終わってないのですぐにはマスターに昇格しません。
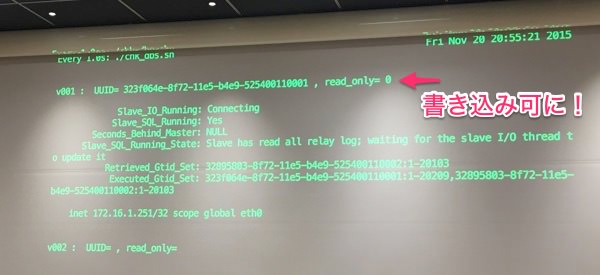
無事binlogの適用が終わると書き込み可能になりました(拍手)
バックアップ、リカバリー
- Percona Xtrabackupがほぼオンラインバックアップ可能らしい
- デイリーでxtrabackupのラッパースクリプトを使ってバックアップしている
バックアップデモ
こんなスクリプトでバックアップを取ります
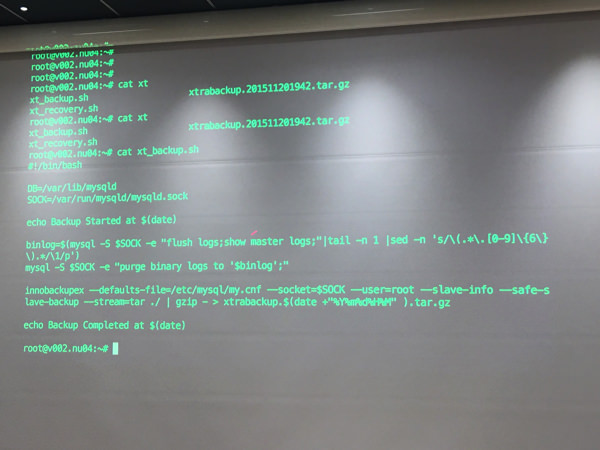
ものすごい速さでバックアップ取得完了。
@ktaka氏「すごい速いですよね?データベース空なんです」
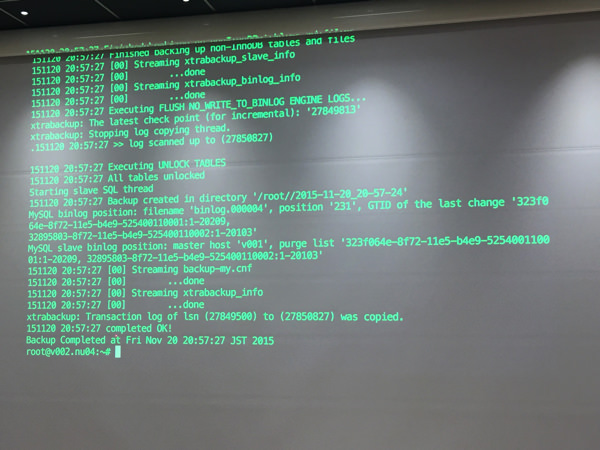
リカバリする前のUUIDは32895803…を覚えておく。
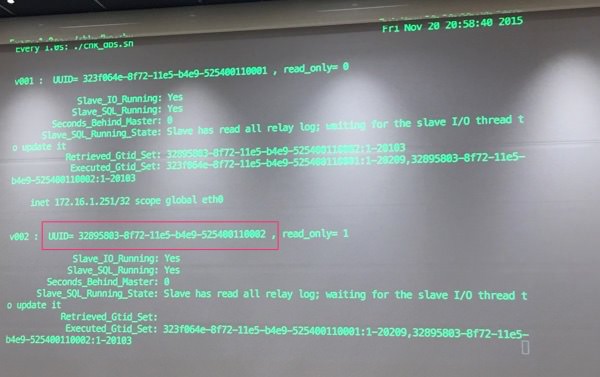
実際にリカバリシェルを動かしてみます。
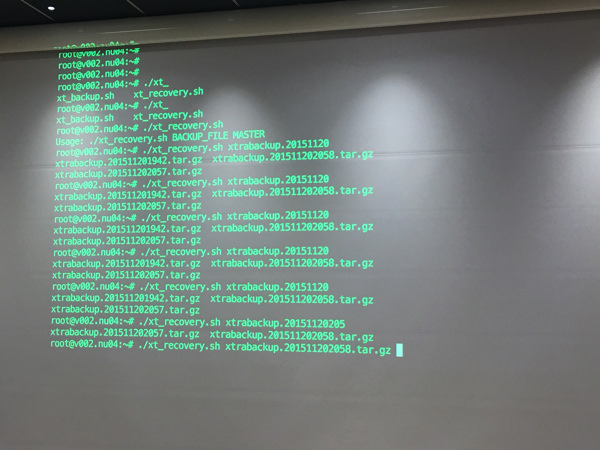
ファイルを置き換えてリカバリしている様子(リカバリというよりはリストア?)
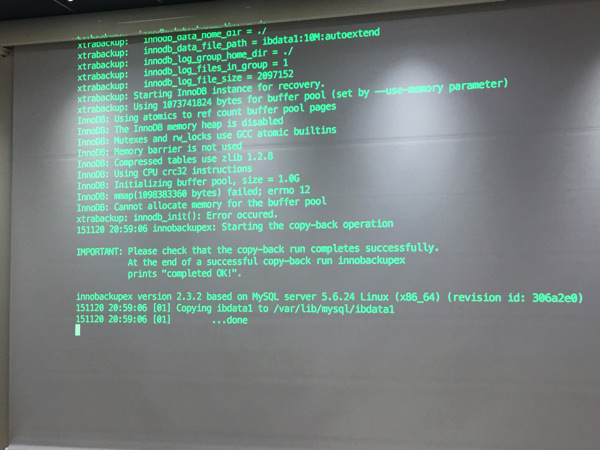
無事リカバリ終了
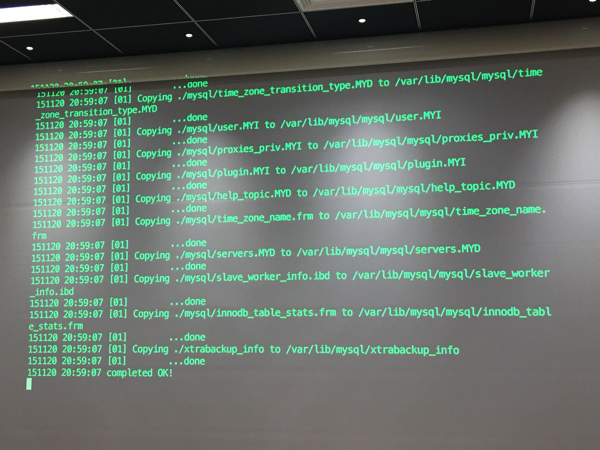
リカバリ後、自動的にスレーブへ復旧もします。
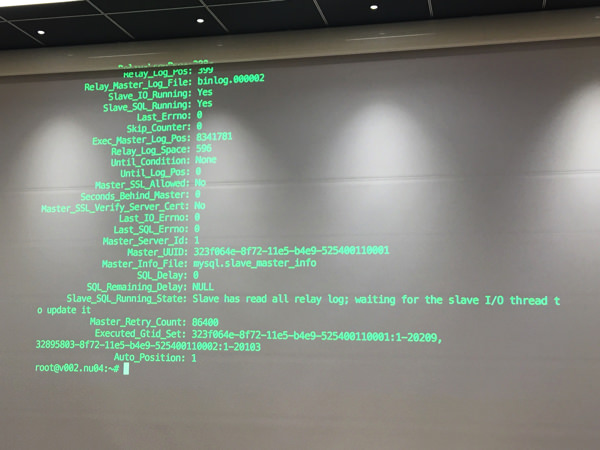
リカバリ後のUUIDが1bfac168…に変わっており、無事リカバリされたことがわかる。

ちなみにxtrabackupは100万件入っているレコードでも、レプリケーションに復活させるの早かったのでオススメとのこと
まとめ
- ほぼ瞬時にフェイルオーバー
- xtrabackupはバックアップリカバリーが速い
- 課題
- マルチマスターなので不整合に気をつける
- レプリケーションが遅いとなかなか昇格できない。5.7に期待
- バックアップファイルの正しさチェックはどうするのか?
MySQL5.7とMariaDB10.1の性能比較(簡易)

- mariaDBでcommodity hardwareでの検証は4core cpuで64Gあるのに、innodb_buffer_pool_sizeは512mで試している!?
- @markcallaghan氏はほとんど2scoketじゃないかとつっこんでいた
- commodity hardwareは2cpuくらいまでおkな環境の模様
環境
- innodb_flush_neighborsの設定に注意
- iblogfileが合計16G
- 検証環境2はIODrive2
- 検証環境3はSASでした
sysbench
- 8並列で実行しています
- mariadbと同じことをやろうとしています
LinkBench
- 64スレッドで実行
結果
- 3回とった平均のグラフですが、基本的にはmariaのほうが速い
- 8coreになると均衡するがoltpだと少し差がでる
- mariaはスレッドが増えると少し性能が落ちた
- read onlyではmariaのほうが優勢
- コア数が増えるとMySQlのほうが優勢になる可能性がある
Linkbenchの結果
- mysqlのほうが速い
- read writeのmutexが早くなったのでMySQL5.7は速い
- iblog周りの処理も早くなった
- 環境3はfsyncが遅くなって更新がネックになっている
まとめ
- readlonlyならmaria, read writeならmysqlがいい
- readonlyとか特殊な環境でやるならKVS使え
- mariadbはベンチマーク結果は情報が少ない
- mariaのほうがはやい場合もあるので環境によって取得してみましょう
Openstack(trove)におけるMySQL
前川様が作った資料を三島様が発表!(新しい!)
Troveについて
- OpenStackに実装されたDBaaSで、RDSみたいなもの
- MySQL以外にも使えるが実際に使えるのはほぼMySQLのみ
主要機能
- MySQLの動くサーバの起動したり停止したり、ユーザ作ったり、バックアップ、リストアなどできる
- バックアップは仮想サーバ単位のバックアップになり、mysqldumpは使えません
Troveのシステム構成
- openstackからMySQLサーバに指示を出さないといけないのでRabbitMQを介してMySQLにアクセスしている
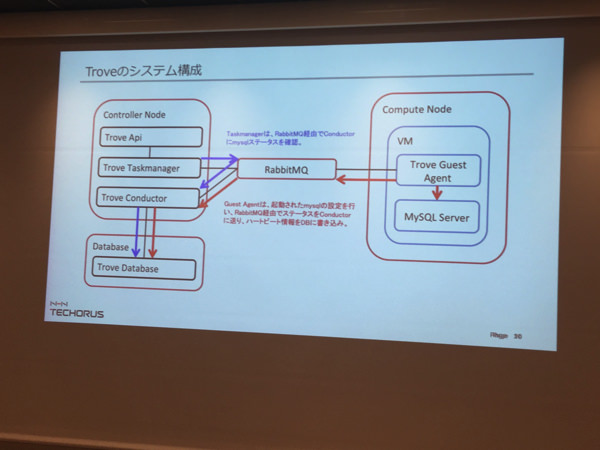
MySQLとの相関
- troveは最近リリースされた
- 半年に1回5.6の対応やperconaの対応などをリリースしている
AWSとの比較
- MySQLをイメージで作成可能だが、機能面で見るとAWSのほうが多い
- プライベートで作るにはいいと思う
メリット
- デプロイが簡単、MySQLイメージの作成が可能
- RDSは決まったバージョンしか使えず、「あれやりたい!」などがはまらないと自分たちでMySQLを立てるという形になる
デメリット
- クラウド上で標準化されたサービスを提供するというものなので細かいチューニングが出来ない
- ダッシュボードだけでは全機能が使えないが、基本的なところは使える
- trove使った時にはsshでmysqlにアクセスすることは出来ない
- 新しい機能を使いたいたいときは自分で機能を作ったりしないといけない
- 運用を考えた時に弱点がログの確認が出来ない。専用の監視サービスなどもない
まとめ
- 社内のプライベートクラウドでDBaaSでTroveはいい
- しかし、細かいどころに手がとどかないので使い分ける必要がある
- 大規模な環境で標準化して大量に作るときはtroveはいいが、要件ごとにカスタマイズしたMySQLなどを使いたいなら個別の仮想サーバをたててMySQLを作るのがいい
- 構築は発展途上で動かないところもある
N対1 レプリケーション + Optimizer Hint

- N:1 レプリケーションはマスターが複数あり、一つのスレーブに集約する機能
- change masterを使って順次レプリケーションを行ってやった
- N1Replというのがgithubに上がっています
- ごく一部の人からは「どあきレプリケーション」とよばれている
- インドのどこかの会社の本番環境で使われているらしい
- 無停止稼働で通算4年動いてます
- Multi-source ReplicationがMySQL5.7に搭載されました!
- どあきレプリケーションとちがうのはchannnelという名前をつけて並列でスレーブにアクセスできる
- GTID不要で使えるらしい
- 同時に繋ぐので、大規模だと一気にスレーブにデータが来て帯域に問題が起こるのではないと思われる
- もうどあきレプリケーション不要?
QueryCache
- セッションレベルやステートメントレベルで設定ができる
- 小規模であるときはquerycacheをONにするだけでパフォーマンスが上がる
Optimizer Hints
- MySQLのオプティマイザーはいくつかのプランをたてて、ジョインの仕方やインデックスの仕方の戦略を建てているが、それを選択するのがいままでglobal/session単位でしかできなかったのが、optimizer hintsを使うとステートメント単位でつかえるようになった
- 有効にしたところで確実に使われるわけではないが、優先的に使ってくれる
- いままでチューニングしていたSQLがはやくなっていたものが、ICP入ることで遅くなる場合はNO_ICPヒントを入れることで元の挙動になって速さが戻ることもある
- OptimizerHintsを使う上で注意すること
- SELECTの直後じゃないとヒントききません
- MySQLのコメントでこのバージョン以降で使うといったこともできる
- バージョン指定と一緒に使う場合は空白なしでやらないと使えない
- query cacheからするとヒント句変わっただけでも別クエリとしてキャッシュされます
- MAX_EXECUTION_TIME:クエリ実行にタイムアウトを設定できる
- 5.7.8より前はMAX_STATEMENT_TIME
- 問題としてはmax_exectuion_timeでぐぐると、PHPの話がいっぱいひっかかる
- MySQL5.7じゃないけど、MAX_ECECUTION_TIMEを使いたい人はphp で mysql の max_execution_time Optimizer Hint を模倣するサンプル参照
まとめ
- N:1Replication動いてます
- OptimizerHints便利
Prepared statements on MySQL in Ruby

- phpだとPDOみたいなRDBの共通化DBIがあるが、RubyのMySQLバインディングは他の言語と違い、DBIが全く流行っていない
- rubyでいうとmysqlに接続するためのバインディングはmysql-gem, mysql2などがある
- mysql2はrubyっぽいインターフェースで使えるが、prepared statementsをサポートしていない
- でもrubyはそういうのこだわらない!!
- 困ったのはISUCONの出題側をやった時、破滅的な挙動で死んだ
- rubyの実装の時に、今までpreapred statementサポートしていなかったmysql2がサポートし始めたので使ってみたら破滅的だった
- preaparedしてexecuteを700回くらいやるとすぐにcr_commands_out_of_syncというエラーを頻繁に出した
- 真のprepated statementではないが、?にうまいことbindしてくれるtagomoris/mysql2-cs-bindを使った
- preparedしてexecuteして、gc_startさせて強制的にガベージコレクションをすると死ぬほど遅くなるが、エラーが発生しなくなる
- 出題が終わった後に治そうとしたら既にprepared statementをcloseする実装されていた
- やってみたらめちゃめちゃセぐりまくった
- 確保したものは開放するというのをPRだしたのだが、放置されている
- どうやらruby的に言うと、リソースをプログラマーが明示的に開放するのは好みじゃないらしく、別実装がきた
- 開放するのを放棄するという実装
- ユーザーは開放するということにさいなまれることはない
- 最初の問題はまだ特定できてないのでこの実装でもいいかなと思っている
- rubyでprepared statementsをサポートしてないせいで、railsも困っているので、頑張ってActiveRecord用のMysql2Adpterを作ってみました
- rubyでrailsでpreapred statementsが使えるようになるはず!
- これが入れば古いライブラリのサポートが切れるはず
- (けど筆者が今朝みたらMySQL2にいれろとのことでcloseされている・・・)
最後
- 数字で見るカジュアル
- 一人あたり15分
- どんなネタでもいいので次回以降も気軽に出てきて欲しいです
- slackにもはれば捗るのでは
- 次回は2016/01/22,Yahoo Japanで開かれます
- こっちは大規模な話が聞けるはず!
- 俺こそがカジュアルという人は連絡下さい!!
- MySQL Casual Advent Calendar 2015 すごい空いてるので書いてね♡
@mogmetの所感
最近はMySQLをいじる機会がないのであまり最新情報などは終えていなかったのですが、5.7での全文検索日本語サポートや、スレーブのマルチでの適用、Optimizer hints、Multi-source Replicationなどなどキャッチアップできることが多くて参加できてとてもよかったです。
heartbeatを使ったフェイルオーバーデモは失敗も華麗にカバーする素敵なデモでとてもいいデモでした。
demoを見ていて、heartbeatの仕組みはそういえば前の会社でも使ってたような気がしましたが、前の会社のDBは挙動的に大丈夫かな・・・とふと思ってしまいました。(きっともう古いからなくなるはず・・・だからきっと大丈夫ですよね?)











